Hooked on Feelings
Introduction
This is a deeper exploration of mapping with a purpose. In this case, we are going to map the results of the 2016 Presidential Election. For a look at the maps we are going to do, take a look at this Washington Post article.
Preliminary Items
First Things First! Download the script and data set
Please download all of the materials needed for this walkthrough and put them all in a folder by themselves.
Set your Working Directory
Your working directory is simply where your script will look for anything it needs like external data sets. There are a few ways to go about doing this which we will cover. However for now, just do the following:
- Open up the included script by going to
File > Open Fileor double click the file itself if RStudio is your default program for opening.Rfiles. - To set your working directory:
- Go to the menu bar and select
Session > Set Working Directory > To Source File LocationOR - run
setwd(dirname(rstudioapi::getActiveDocumentContext()$path))1
Loading libraries
Go ahead and load these or install and then load them.
library(tidyverse)
library(tidytext)
library(glue)We should first take a look at the new ones being used here
| Library | Description | Repository | Example |
|---|---|---|---|
tidyverse | Nope | Github | Tutorial |
tidytext | Provides the tools to make a text mining experience tidy | Github | Vignette |
glue | A tidyverse package that gives the power to concatenate strings in a way that’s tidy | Github | Vignette |
Loading Data
We’ll be using text data, in particular state of the union speeches. These are annual narratives by the President of the United States given to a joint session of congress. In each, the President reviews the previous year and lays out his legislative agenda for the coming year. This dataset contains the full text of the State of the Union address from 1989 (Reagan) to 2017 (Trump).
Let’s get a list of the files in the directory
files <-
list.files("state-of-the-union-corpus-1989-2017")
files## [1] "Bush_1989.txt" "Bush_1990.txt" "Bush_1991.txt" "Bush_1992.txt"
## [5] "Bush_2001.txt" "Bush_2002.txt" "Bush_2003.txt" "Bush_2004.txt"
## [9] "Bush_2005.txt" "Bush_2006.txt" "Bush_2007.txt" "Bush_2008.txt"
## [13] "Clinton_1993.txt" "Clinton_1994.txt" "Clinton_1995.txt" "Clinton_1996.txt"
## [17] "Clinton_1997.txt" "Clinton_1998.txt" "Clinton_1999.txt" "Clinton_2000.txt"
## [21] "Obama_2009.txt" "Obama_2010.txt" "Obama_2011.txt" "Obama_2012.txt"
## [25] "Obama_2013.txt" "Obama_2014.txt" "Obama_2015.txt" "Obama_2016.txt"
## [29] "Trump_2017.txt"We’ll bring in the first file
files[1]## [1] "Bush_1989.txt"Stick together the path to the file and 1st file name
fileName <- glue("state-of-the-union-corpus-1989-2017/",
files[1],
sep = "") %>%
trimws()
fileName## /Users/skynet/Documents/WVU/Teaching/GitHub.nosync/Workspace/edp693e/static/data/state-of-the-union-corpus-1989-2017Bush_1989.txtread in the text and book_text it up by removing any dollar signs since they mean something different in R
fileText <-
glue(read_file(fileName))
fileText <-
gsub("\\$", "", fileText)
fileText| x |
|---|
Mr. Speaker, Mr. President, and distinguished Members of the House and Senate, honored guests, and fellow citizens:
Less than 3 weeks ago, I joined you on the West Front of this very building and, looking over the monuments to our proud past, offered you my hand in filling the next page of American history with a story of extended prosperity and continued peace. And tonight I’m back to offer you my plans as well. The hand remains extended; the sleeves are rolled up; America is waiting; and now we must produce. Together, we can build a better America.
It is comforting to return to this historic Chamber. Here, 22 years ago, I first raised my hand to be sworn into public life. So, tonight I feel as if I’m returning home to friends. And I intend, in the months and years to come, to give you what friends deserve: frankness, respect, and my best judgment about ways to improve America’s future. In return, I ask for an honest commitment to our common mission of progress. If we seize the opportunities on the road before us, there’ll be praise enough for all. The people didn’t send us here to bicker, and it’s time to govern.
And many Presidents have come to this Chamber in times of great crisis: war and depression, loss of national spirit. And 8 years ago, I sat in that very chair as President Reagan spoke of punishing inflation and devastatingly high interest rates and people out of work — American confidence on the wane. And our challenge is different. We’re fortunate — a much changed landscape lies before us tonight. So, I don’t propose to reverse direction. We’re headed the right way, but we cannot rest. We’re a people whose energy and drive have fueled our rise to greatness. And we’re a forward-looking nation — generous, yes, but ambitious, not for ourselves but for the world. Complacency is not in our character — not before, not now, not ever.
And so, tonight we must take a strong America and make it even better. We must address some very real problems. We must establish some very clear priorities. And we must make a very substantial cut in the Federal budget deficit. Some people find that agenda impossible, but I’m presenting to you tonight a realistic plan for tackling it. My plan has four broad features: attention to urgent priorities, investment in the future, an attack on the deficit, and no new taxes. This budget represents my best judgment of how we can address our priorities. There are many areas in which we would all like to spend more than I propose; I understand that. But we cannot until we get our fiscal house in order.
Next year alone, thanks to economic growth, without any change in the law, the Federal Government will take in over 80 billion more than it does this year. That’s right — over 80 billion in new revenues, with no increases in taxes. And our job is to allocate those new resources wisely. We can afford to increase spending by a modest amount, but enough to invest in key priorities and still cut the deficit by almost 40 percent in 1 year. And that will allow us to meet the targets set forth in the Gramm-Rudman-Hollings law. But to do that, we must recognize that growth above inflation in Federal programs is not preordained, that not all spending initiatives were designed to be immortal.
I make this pledge tonight: My team and I are ready to work with the Congress, to form a special leadership group, to negotiate in good faith, to work day and night — if that’s what it takes — to meet the budget targets and to produce a budget on time.
We cannot settle for business as usual. Government by continuing resolution, or government by crisis, will not do. And I ask the Congress tonight to approve several measures which will make budgeting more sensible. We could save time and improve efficiency by enacting 2-year budgets. Forty-three Governors have the line-item veto. Presidents should have it, too. And at the very least, when a President proposes to rescind Federal spending, the Congress should be required to vote on that proposal instead of killing it by inaction. And I ask the Congress to honor the public’s wishes by passing a constitutional amendment to require a balanced budget. Such an amendment, once phased in, will discipline both the Congress and the executive branch.
Several principles describe the kind of America I hope to build with your help in the years ahead. We will not have the luxury of taking the easy, spendthrift approach to solving problems because higher spending and higher taxes put economic growth at risk. Economic growth provides jobs and hope. Economic growth enables us to pay for social programs. Economic growth enhances the security of the Nation, and low tax rates create economic growth.
I believe in giving Americans greater freedom and greater choice. And I will work for choice for American families, whether in the housing in which they live, the schools to which they send their children, or the child care they select for their young. You see, I believe that we have an obligation to those in need, but that government should not be the provider of first resort for things that the private sector can produce better. I believe in a society that is free from discrimination and bigotry of any kind. And I will work to knock down the barriers left by past discrimination and to build a more tolerant society that will stop such barriers from ever being built again.
I believe that family and faith represent the moral compass of the Nation. And I’ll work to make them strong, for as Benjamin Franklin said: If a sparrow cannot fall to the ground without His notice, can a great nation rise without His aid? And I believe in giving people the power to make their own lives better through growth and opportunity. And together, let's put power in the hands of people. Three weeks ago, we celebrated the bicentennial inaugural, the 200th anniversary of the first Presidency. And if you look back, one thing is so striking about the way the Founding Fathers looked at America. They didn't talk about themselves. They talked about posterity. They talked about the future. And we, too, must think in terms bigger than ourselves. We must take actions today that will ensure a better tomorrow. We must extend American leadership in technology, increase long-term investment, improve our educational system, and boost productivity. These are the keys to building a better future, and here are some of my recommendations: I propose almost 2.2 billion for the National Science Foundation to promote basic research and keep us on track to double its budget by 1993. I propose to make permanent the tax credit for research and development. I've asked Vice President Quayle to chair a new Task Force on Competitiveness. And I request funding for NASA [National Aeronautics and Space Administration] and a strong space program, an increase of almost 2.4 billion over the current fiscal year. We must have a manned space station; a vigorous, safe space shuttle program; and more commercial development in space. The space program should always gofull throttle up. And that’s not just our ambition; it’s our destiny.
I propose that we cut the maximum tax rate on capital gains to increase long-term investment. History on this is clear — this will increase revenues, help savings, and create new jobs. We won’t be competitive if we leave whole sectors of America behind. This is the year we should finally enact urban enterprise zones and bring hope to the inner cities.
But the most important competitiveness program of all is one which improves education in America. When some of our students actually have trouble locating America on a map of the world, it is time for us to map a new approach to education. We must reward excellence and cut through bureaucracy. We must help schools that need help the most. We must give choice to parents, students, teachers, and principals; and we must hold all concerned accountable. In education, we cannot tolerate mediocrity. I want to cut that dropout rate and make America a more literate nation, because what it really comes down to is this: The longer our graduation lines are today, the shorter our unemployment lines will be tomorrow.
So, tonight I’m proposing the following initiatives: the beginning of a 500 million program to reward America’s best schools, merit schools; the creation of special Presidential awards for the best teachers in every State, because excellence should be rewarded; the establishment of a new program of National Science Scholars, one each year for every Member of the House and Senate, to give this generation of students a special incentive to excel in science and mathematics; the expanded use of magnet schools, which give families and students greater choice; and a new program to encourage alternative certification, which will let talented people from all fields teach in our classrooms. I’ve said I’d like to be the Education President. And tonight, I'd ask you to join me by becoming theEducation Congress.
Just last week, as I settled into this new office, I received a letter from a mother in Pennsylvania who had been struck by my message in the Inaugural Address. Not 12 hours before, she wrote,my husband and I received word that our son was addicted to cocaine. He had the world at his feet. Bright, gifted, personable — he could have done anything with his life. And now he has chosen cocaine. And please, she wrote,find a way to curb the supply of cocaine. Get tough with the pushers. Our son needs your help.
My friends, that voice crying out for help could be the voice of your own neighbor, your own friend, your own son. Over 23 million Americans used illegal drugs last year, at a staggering cost to our nation’s well-being. Let this be recorded as the time when America rose up and said no to drugs. The scourge of drugs must be stopped. And I am asking tonight for an increase of almost a billion dollars in budget outlays to escalate the war against drugs. The war must be waged on all fronts. Our new drug czar, Bill Bennett, and I will be shoulder to shoulder in the executive branch leading the charge.
Some money will be used to expand treatment to the poor and to young mothers. This will offer the helping hand to the many innocent victims of drugs, like the thousands of babies born addicted or with AIDS because of the mother’s addiction. Some will be used to cut the waiting time for treatment. Some money will be devoted to those urban schools where the emergency is now the worst. And much of it will be used to protect our borders, with help from the Coast Guard and the Customs Service, the Departments of State and Justice, and, yes, the U.S. military.
I mean to get tough on the drug criminals. And let me be clear: This President will back up those who put their lives on the line every single day — our local police officers. My budget asks for beefed-up prosecution, for a new attack on organized crime, and for enforcement of tough sentences — and for the worst kingpins, that means the death penalty. I also want to make sure that when a drug dealer is convicted there’s a cell waiting for him. And he should not go free because prisons are too full. And so, let the word go out: If you’re caught and convicted, you will do time.
But for all we do in law enforcement, in interdiction and treatment, we will never win this war on drugs unless we stop the demand for drugs. So, some of this increase will be used to educate the young about the dangers of drugs. We must involve the parents. We must involve the teachers. We must involve the communities. And, my friends, we must involve ourselves, each and every one of us in this concern.
One problem related to drug use demands our urgent attention and our continuing compassion, and that is the terrible tragedy of AIDS. I’m asking for 1.6 billion for education to prevent the disease and for research to find a cure.
If we’re to protect our future, we need a new attitude about the environment. We must protect the air we breathe. I will send to you shortly legislation for a new, more effective Clean Air Act. It will include a plan to reduce by date certain the emissions which cause acid rain, because the time for study alone has passed, and the time for action is now. We must make use of clean coal. My budget contains full funding, on schedule, for the clean coal technology agreement that we’ve made with Canada. We’ve made that agreement with Canada, and we intend to honor that agreement. We must not neglect our parks. So, I’m asking to fund new acquisitions under the Land and Water Conservation Fund. We must protect our oceans. And I support new penalties against those who would dump medical waste and other trash into our oceans. The age of the needle on the beaches must end.
And in some cases, the gulfs and oceans off our shores hold the promise of oil and gas reserves which can make our nation more secure and less dependent on foreign oil. And when those with the most promise can be tapped safely, as with much of the Alaska National Wildlife Refuge, we should proceed. But we must use caution; we must respect the environment. And so, tonight I’m calling for the indefinite postponement of three lease sales which have raised troubling questions, two off the coast of California and one which could threaten the Everglades in Florida. Action on these three lease sales will await the conclusion of a special task force set up to measure the potential for environmental damage.
I’m directing the Attorney General and the Administrator of the Environmental Protection Agency to use every tool at their disposal to speed and toughen the enforcement of our laws against toxic-waste dumpers. I want faster cleanups and tougher enforcement of penalties against polluters.
In addition to caring for our future, we must care for those around us. A decent society shows compassion for the young, the elderly, the vulnerable, and the poor. Our first obligation is to the most vulnerable — infants, poor mothers, children living in poverty — and my proposed budget recognizes this. I ask for full funding of Medicaid, an increase of over 3 billion, and an expansion of the program to include coverage of pregnant women who are near the poverty line. I believe we should help working families cope with the burden of child care. Our help should be aimed at those who need it most: low-income families with young children. I support a new child care tax credit that will aim our efforts at exactly those families, without discriminating against mothers who choose to stay at home.
Now, I know there are competing proposals. But remember this: The overwhelming majority of all preschool child care is now provided by relatives and neighbors and churches and community groups. Families who choose these options should remain eligible for help. Parents should have choice. And for those children who are unwanted or abused or whose parents are deceased, we should encourage adoption. I propose to reenact the tax deduction for adoption expenses and to double it to 3,000. Let’s make it easier for these kids to have parents who love them.
We have a moral contract with our senior citizens. And in this budget, Social Security is fully funded, including a full cost-of-living adjustment. We must honor our contract.
We must care about those in the shadow of life, and I, like many Americans, am deeply troubled by the plight of the homeless. The causes of homelessness are many; the history is long. But the moral imperative to act is clear. Thanks to the deep well of generosity in this great land, many organizations already contribute, but we in government cannot stand on the sidelines. In my budget, I ask for greater support for emergency food and shelter, for health services and measures to prevent substance abuse, and for clinics for the mentally ill. And I propose a new initiative involving the full range of government agencies. We must confront this national shame.
There’s another issue that I’ve decided to mention here tonight. I’ve long believed that the people of Puerto Rico should have the right to determine their own political future. Personally, I strongly favor statehood. But I urge the Congress to take the necessary steps to allow the people to decide in a referendum.
Certain problems, the result of decades of unwise practices, threaten the health and security of our people. Left unattended, they will only get worse. But we can act now to put them behind us.
Earlier this week, I announced my support for a plan to restore the financial and moral integrity of our savings system. I ask Congress to enact our reform proposals within 45 days. We must not let this situation fester. We owe it to the savers in this country to solve this problem. Certainly, the savings of Americans must remain secure. Let me be clear: Insured depositors will continue to be fully protected, but any plan to refinance the system must be accompanied by major reform. Our proposals will prevent such a crisis from recurring. The best answer is to make sure that a mess like this will never happen again. The majority of thrifts in communities across the Nation have been honest. They’ve played a major role in helping families achieve the dream of home ownership. But make no mistake, those who are corrupt, those who break the law, must be kicked out of the business; and they should go to jail.
We face a massive task in cleaning up the waste left from decades of environmental neglect at America’s nuclear weapons plants. Clearly, we must modernize these plants and operate them safely. That’s not at issue; our national security depends on it. But beyond that, we must clean up the old mess that’s been left behind. And I propose in this budget to more than double our current effort to do so. This will allow us to identify the exact nature of the various problems so we can clean them up, and clean them up we will.
We’ve been fortunate during these past 8 years. America is a stronger nation than it was in 1980. Morale in our Armed Forces has been restored; our resolve has been shown. Our readiness has been improved, and we are at peace. There can no longer be any doubt that peace has been made more secure through strength. And when America is stronger, the world is safer.
Most people don’t realize that after the successful restoration of our strength, the Pentagon budget has actually been reduced in real terms for each of the last 4 years. We cannot tolerate continued real reduction in defense. In light of the compelling need to reduce the deficit, however, I support a 1-year freeze in the military budget, something I proposed last fall in my flexible freeze plan. And this freeze will apply for only 1 year, and after that, increases above inflation will be required. I will not sacrifice American preparedness, and I will not compromise American strength.
I should be clear on the conditions attached to my recommendation for the coming year: The savings must be allocated to those priorities for investing in our future that I’ve spoken about tonight. This defense freeze must be a part of a comprehensive budget agreement which meets the targets spelled out in Gramm-Rudman-Hollings law without raising taxes and which incorporates reforms in the budget process.
I’ve directed the National Security Council to review our national security and defense policies and report back to me within 90 days to ensure that our capabilities and resources meet our commitments and strategies. I’m also charging the Department of Defense with the task of developing a plan to improve the defense procurement process and management of the Pentagon, one which will fully implement the Packard commission report. Many of these changes can only be made with the participation of the Congress, and so, I ask for your help. We need fewer regulations. We need less bureaucracy. We need multiyear procurement and 2-year budgeting. And frankly — and don’t take this wrong — we need less congressional micromanagement of our nation’s military policy. I detect a slight division on that question, but nevertheless.
Securing a more peaceful world is perhaps the most important priority I’d like to address tonight. You know, we meet at a time of extraordinary hope. Never before in this century have our values of freedom, democracy, and economic opportunity been such a powerful and intellectual force around the globe. Never before has our leadership been so crucial, because while America has its eyes on the future, the world has its eyes on America.
And it’s a time of great change in the world, and especially in the Soviet Union. Prudence and common sense dictate that we try to understand the full meaning of the change going on there, review our policies, and then proceed with caution. But I’ve personally assured General Secretary Gorbachev that at the conclusion of such a review we will be ready to move forward. We will not miss any opportunity to work for peace. The fundamental facts remain that the Soviets retain a very powerful military machine in the service of objectives which are still too often in conflict with ours. So, let us take the new openness seriously, but let’s also be realistic. And let’s always be strong.
There are some pressing issues we must address. I will vigorously pursue the Strategic Defense Initiative. The spread, and even use, of sophisticated weaponry threatens global security as never before. Chemical weapons must be banned from the face of the Earth, never to be used again. And look, this won’t be easy. Verification — extraordinarily difficult, but civilization and human decency demand that we try. And the spread of nuclear weapons must be stopped. And I’ll work to strengthen the hand of the International Atomic Energy Agency. Our diplomacy must work every day against the proliferation of nuclear weapons.
And around the globe, we must continue to be freedom’s best friend. And we must stand firm for self-determination and democracy in Central America, including in Nicaragua. It is my strongly held conviction that when people are given the chance they inevitably will choose a free press, freedom of worship, and certifiably free and fair elections.
We must strengthen the alliance of the industrial democracies, as solid a force for peace as the world has ever known. And this is an alliance forged by the power of our ideals, not the pettiness of our differences. So, let’s lift our sights to rise above fighting about beef hormones, to building a better future, to move from protectionism to progress.
I’ve asked the Secretary of State to visit Europe next week and to consult with our allies on the wide range of challenges and opportunities we face together, including East-West relations. And I look forward to meeting with our NATO partners in the near future.
And I, too, shall begin a trip shortly to the far reaches of the Pacific Basin, where the winds of democracy are creating new hope and the power of free markets is unleashing a new force. When I served as our representative in China 14 or 15 years ago, few would have predicted the scope of the changes we’ve witnessed since then. But in preparing for this trip, I was struck by something I came across from a Chinese writer. He was speaking of his country, decades ago, but his words speak to each of us in America tonight. Today, he said,we’re afraid of the simple words like goodness' andmercy’ and `kindness.’ My friends, if we’re to succeed as a nation, we must rediscover those words.
In just 3 days, we mark the birthday of Abraham Lincoln, the man who saved our Union and gave new meaning to the word opportunity. Lincoln once said:I hold that while man exists, it is his duty to improve not only his own condition but to assist in ameliorating that of mankind. It is this broader mission to which I call all Americans, because the definition of a successful life must include serving others.
And to the young people of America, who sometimes feel left out, I ask you tonight to give us the benefit of your talent and energy through a new program called YES, for Youth Entering Service to America.
To those men and women in business, remember the ultimate end of your work: to make a better product, to create better lives. I ask you to plan for the longer term and avoid that temptation of quick and easy paper profits.
To the brave men and women who wear the uniform of the United States of America, thank you. Your calling is a high one: to be the defenders of freedom and the guarantors of liberty. And I want you to know that this nation is grateful for your service.
To the farmers of America, we appreciate the bounty you provide. We will work with you to open foreign markets to American agricultural products.
And to the parents of America, I ask you to get involved in your child’s schooling. Check on the homework, go to the school, meet the teachers, care about what is happening there. It’s not only your child’s future on the line, it’s America’s.
To kids in our cities, don’t give up hope. Say no to drugs; stay in school. And, yes, Keep hope alive. To those 37 million Americans with some form of disability, you belong in the economic mainstream. We need your talents in America's work force. Disabled Americans must become full partners in America's opportunity society. To the families of America watching tonight in your living rooms, hold fast to your dreams because ultimately America's future rests in your hands. And to my friends in this Chamber, I ask your cooperation to keep America growing while cutting the deficit. That's only fair to those who now have no vote: the generations to come. Let them look back and say that we had the foresight to understand that a time of peace and prosperity is not the time to rest but a time to press forward, a time to invest in the future. And let all Americans remember that no problem of human making is too great to be overcome by human ingenuity, human energy, and the untiring hope of the human spirit. I believe this. I would not have asked to be your President if I didn't. And tomorrow the debate on the plan I've put forward begins, and I ask the Congress to come forward with your own proposals. Let's not question each other's motives. Let's debate, let's negotiate; but let us solve the problem. Recalling anniversaries may not be my specialty in speeches but tonight is one of some note. On February 9th, 1941, just 48 years ago tonight, Sir Winston Churchill took to the airwaves during Britain's hour of peril. He'd received from President Roosevelt a hand-carried letter quoting Longfellow's famous poem:Sail on, O Ship of State! Sail on, O Union, strong and great! Humanity with all its fears, With all the hopes of future years, Is hanging breathless on thy fate! And Churchill responded on this night by radio broadcast to a nation at war, but he directed his words to Franklin Roosevelt. We shall not fail or falter, he said.We shall not weaken or tire. Give us the tools, and we will finish the job.
Tonight, almost half a century later, our peril may be less immediate, but the need for perseverance and clear-sighted fortitude is just as great. Now, as then, there are those who say it can’t be done. There are voices who say that America’s best days have passed, that we’re bound by constraints, threatened by problems, surrounded by troubles which limit our ability to hope. Well, tonight I remain full of hope. We Americans have only begun on our mission of goodness and greatness. And to those timid souls, I repeat the plea: ``Give us the tools, and we will do the job.
Thank you. God bless you, and God bless America. |
Understanding NLP
In a nutshell, computers and people don’t view or “understand” text in the same way - enter Natural Language Processing (NLP). Part of artificial intelligence, NLP acts as a middleman that deals with the reading, deciphering and understanding of natural language used by computers and humans. Some things you can do with this include the following with possible questions that address each method
Authorship identification: Can you correctly identify the author of a previously unseen address?
Parsing: Can you train implement a parser to automatically extract the syntactic relationships between words?
Sentiment analysis: Are there differences in tone between different Presidents? Presidents from different parties?
Topic modeling: Which topics have become more popular over time? Which have become less popular?
Sentiment Analysis
What is it?
A sentiment analysis is the computational task of automatically determining what feelings a writer is expressing in text. Sentiment is often framed as a binary distinction (positive vs. negative), but it can also be a more fine-grained, like identifying the specific emotion an author is expressing (like fear, joy or anger).
It is used for many applications, especially in assessing consumers. Some examples of applications for sentiment analysis include
Analyzing the social media discussion around a certain topic
Evaluating survey responses
Determining whether product reviews are polar and to what degree
A sentiment analysis is not perfect and as with any automatic analysis of language, you will have errors in your results. It also cannot tell you why a writer is feeling a certain way. However, it can be useful to quickly summarize some qualities of text, especially if you have so much text that a human reader cannot analyze all of it.
How Does it Work?
There are many ways to do sentiment analysis and most approaches use the same general idea
Create or find a list of words associated with strongly positive or negative sentiment.
Count the number of positive and negative words in the text.
Analyze the mix of positive to negative words. Many positive words and few negative words indicates positive sentiment, while many negative words and few positive words indicates negative sentiment.
What is an Example?
The first step, creating or finding a word list (also called a lexicon), is generally the most time-consuming. While you can often use a lexicon that already exists, if your text is discussing a specific topic you may need to add to or modify it.
Sick is an example of a word that can have positive or negative sentiment depending on what it’s used to refer to. If you’re discussing a pet store that sells a lot of sick animals, the sentiment is probably negative. On the other hand, if you’re talking about a skateboarding instructor who taught you how to do a lot of sick flips, the sentiment is probably very positive.
What are the steps?
Generally this is what you have to do
Tokenize
Tokenization is process of taking a bunch of characters (i.e. strings) and chopping the up into little pieces called tokens. Notice that actual “words” are not necessary here. This is important because it will allow us to use parts of words as you’ll see soon!
tokens <-
tibble(text = fileText) %>%
unnest_tokens(word, text)
tokens## # A tibble: 4,822 × 1
## word
## <chr>
## 1 mr
## 2 speaker
## 3 mr
## 4 president
## 5 and
## 6 distinguished
## 7 members
## 8 of
## 9 the
## 10 house
## # … with 4,812 more rowsFilter Stop Words
In text analysis, we tend to remove stop words which are terms that are not useful for an analysis like “and”, “of”, “the”, etc. Here we use anti_join() to get rid of those terms from our data set.
data(stop_words)
tidy_tokens <-
tokens %>%
anti_join(stop_words)
tidy_tokens## # A tibble: 1,886 × 1
## word
## <chr>
## 1 speaker
## 2 president
## 3 distinguished
## 4 house
## 5 senate
## 6 honored
## 7 guests
## 8 fellow
## 9 citizens
## 10 3
## # … with 1,876 more rowsLet’s see a count of the remaining terms
tidy_tokens %>%
count(word, sort = TRUE) ## # A tibble: 1,097 × 2
## word n
## <chr> <int>
## 1 america 24
## 2 tonight 21
## 3 budget 17
## 4 future 15
## 5 time 15
## 6 people 13
## 7 nation 11
## 8 congress 10
## 9 hope 10
## 10 americans 9
## # … with 1,087 more rowsand plot them to get a visual filtering on occurrences greater than five for the sake of space
tidy_tokens %>%
count(word, sort = TRUE) %>%
filter(n > 5) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(n, word, fill=n)) +
geom_col() +
theme_minimal() +
labs(y = NULL) +
scale_fill_viridis_c(option = "E")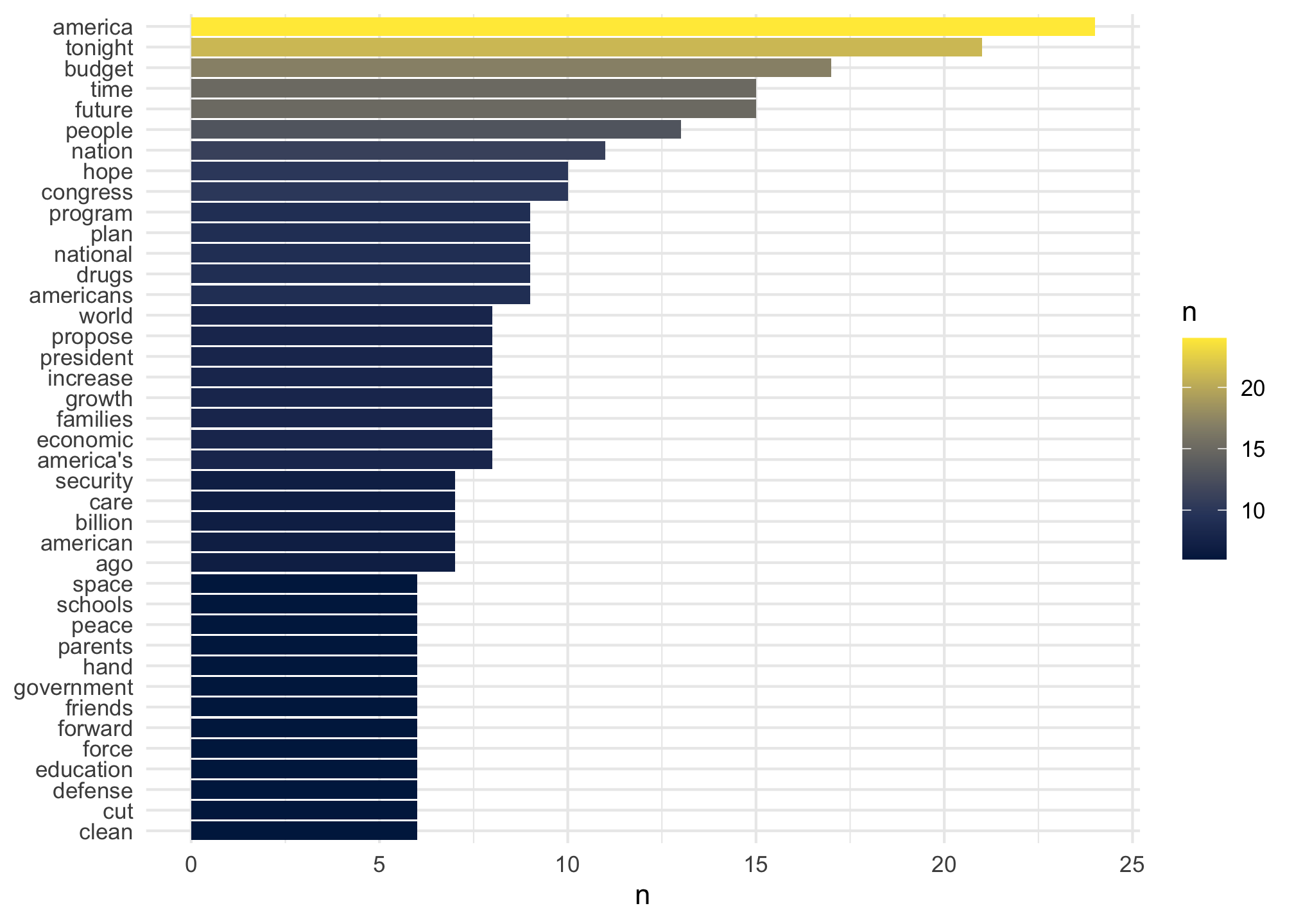
Find Polarities
Now that we have a list of tokens, we need to compare them against a list of words with either positive or negative sentiment.
A list of words associated with a specific sentiment is usually called a sentiment lexicon. Because we’re using the tidytext package, we actually already have some of these lists. I’m going to be using the “bing” list, which was developed by Bing Liu and co-authors.
# Get the sentiment from the first text:
speech_bing_descriptives <- tokens %>%
inner_join(get_sentiments("bing")) %>% # pull out only sentiment words
count(sentiment) %>% # count the # of positive & negative words
spread(sentiment, n, fill = 0) %>% # made data wide rather than narrow
mutate(sentiment = positive - negative) # of positive words - # of negative words
speech_bing_descriptives## # A tibble: 1 × 3
## negative positive sentiment
## <dbl> <dbl> <dbl>
## 1 117 240 123So this text has 117 negative polarity words and 240 positive polarity words. This means that there are 123 more positive than negative words in this text. Now that we know how to get the sentiment for a given text, let’s write a function to do this more quickly and easily and then apply that function to every text in our dataset.
Another Example
The Harry Potter R package harrypotter on GitHub contains the text for all seven books in the Harry Potter series, by JK Rowling. Below, I have included the code required to connect to the package using devtools, as well as the other packages required for the basic text analytics.
Loading libraries
Go ahead and load these or install and then load them.
There is a harrypotter package on CRAN but that is not the one we want. Please run the following instead2.
if (packageVersion("devtools") < 1.6) {
install.packages("devtools")
}
devtools::install_github("bradleyboehmke/harrypotter",
force = TRUE)library(wordcloud)
library(devtools)
library(tidyverse)
library(stringr)
library(tidytext)
library(dplyr)
library(reshape2)
library(igraph)
library(tidygraph)
library(ggraph)
library(harrypotter)
library(widyr)
library(RColorBrewer)
library(viridis)After downloading the data from the harrypotter package on github, we can do a bit of data shaping. The code below places all of the books in the Harry Potter series into a tibble. A tibble is kind of like a data frame, but it has special features that make it optimal for use in the tidyverse. After creating our tibble, we tokenize the text into single words, strip away all punctuation and capitalization, and add columns to the tibble for the book and chapter. In the resulting tibble, you can see each word from the Harry Potter series, and the book/chapter in which it appears.
# note the titles
titles <- c("Philosopher\'s Stone",
"Chamber of Secrets",
"Prisoner of Azkaban",
"Goblet of Fire",
"Order of the Phoenix",
"Half-Blood Prince",
"Deathly Hallows")
titles## [1] "Philosopher's Stone" "Chamber of Secrets" "Prisoner of Azkaban"
## [4] "Goblet of Fire" "Order of the Phoenix" "Half-Blood Prince"
## [7] "Deathly Hallows"# note the data frames
books <- list(philosophers_stone,
chamber_of_secrets,
prisoner_of_azkaban,
goblet_of_fire,
order_of_the_phoenix,
half_blood_prince,
deathly_hallows)# go through the texts and tokenize
series <- tibble()
for(i in seq_along(titles)) {
clean <-
tibble(chapter = seq_along(books[[i]]),
text = books[[i]]) %>%
unnest_tokens(word, text) %>%
mutate(book = titles[i]) %>%
select(book, everything())
series <- rbind(series, clean)
}
series ## # A tibble: 1,089,386 × 3
## book chapter word
## <chr> <int> <chr>
## 1 Philosopher's Stone 1 the
## 2 Philosopher's Stone 1 boy
## 3 Philosopher's Stone 1 who
## 4 Philosopher's Stone 1 lived
## 5 Philosopher's Stone 1 mr
## 6 Philosopher's Stone 1 and
## 7 Philosopher's Stone 1 mrs
## 8 Philosopher's Stone 1 dursley
## 9 Philosopher's Stone 1 of
## 10 Philosopher's Stone 1 number
## # … with 1,089,376 more rows# set factor to keep books in release order
reverse_series <-
series %>%
mutate(book = factor(book,
levels = rev(titles))) %>%
arrange(book)
reverse_series## # A tibble: 1,089,386 × 3
## book chapter word
## <fct> <int> <chr>
## 1 Deathly Hallows 1 the
## 2 Deathly Hallows 1 two
## 3 Deathly Hallows 1 men
## 4 Deathly Hallows 1 appeared
## 5 Deathly Hallows 1 out
## 6 Deathly Hallows 1 of
## 7 Deathly Hallows 1 nowhere
## 8 Deathly Hallows 1 a
## 9 Deathly Hallows 1 few
## 10 Deathly Hallows 1 yards
## # … with 1,089,376 more rowsWe can get simple counts for each word using the count function. The word “the” occurs 51593 times in the Harry Potter series.
reverse_series %>%
count(word, sort = TRUE)## # A tibble: 24,475 × 2
## word n
## <chr> <int>
## 1 the 51593
## 2 and 27430
## 3 to 26985
## 4 of 21802
## 5 a 20966
## 6 he 20322
## 7 harry 16557
## 8 was 15631
## 9 said 14398
## 10 his 14264
## # … with 24,465 more rowsMany of the words in the top ten most frequently appearing words are stop-words such as “the”, “and”, “to”, etc., so let’s discard those for now. Below, you can see a word cloud showing the most frequently occurring non-stop words in the series. The cloud contains the top 50 most frequently occurring words, and the larger a word appears in the cloud, the more frequently that word occurred in the text. It comes as no surprise to Harry Potter readers that most of the largest words in the cloud are names like “Harry”, “Ron” and “Hermione”.
reverse_series %>%
anti_join(stop_words) %>%
count(word,
name = "frequency") %>%
with(wordcloud(word,
frequency,
max.words = 50,
colors = rev(brewer.pal(9,"Spectral"))))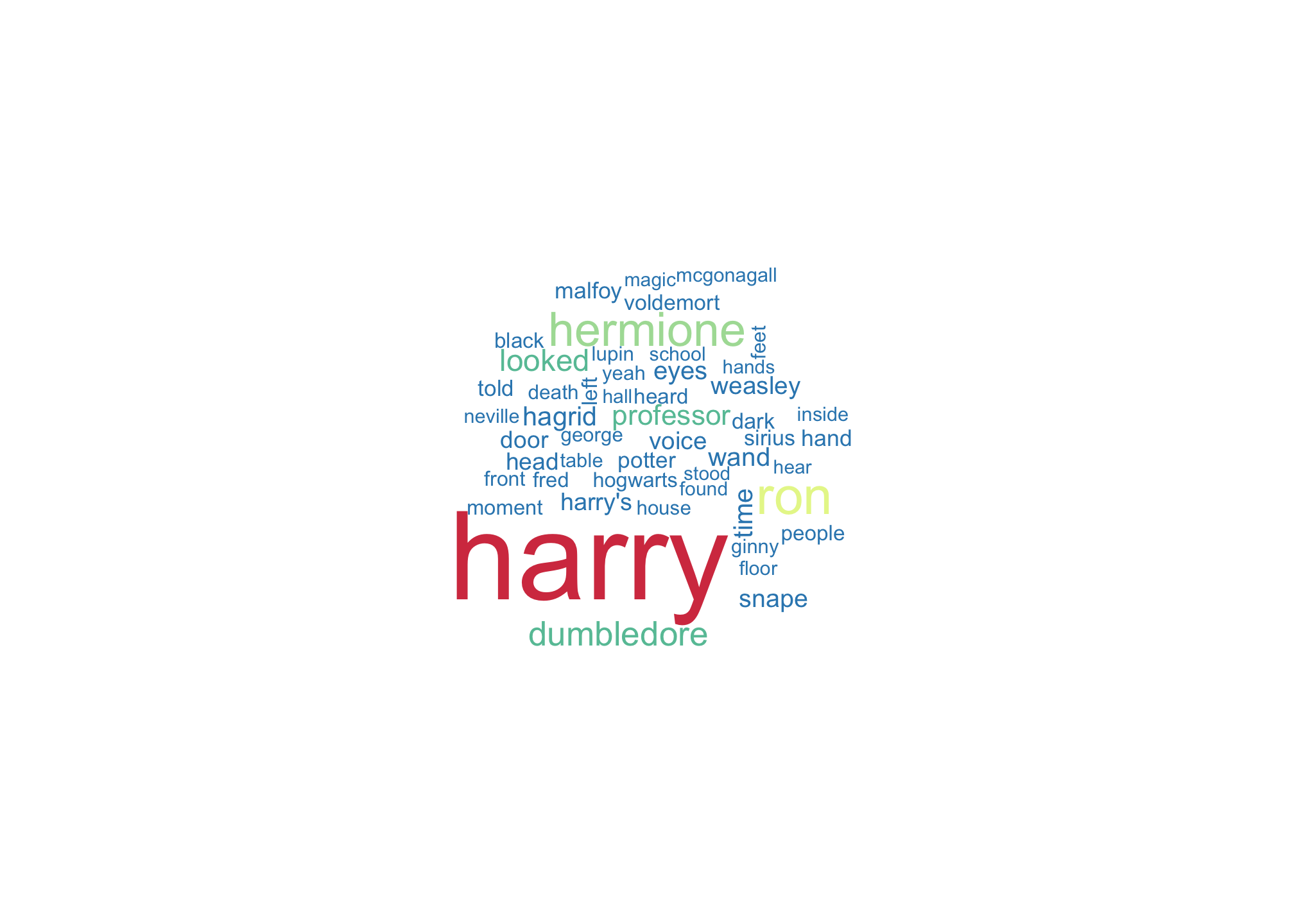
Now we can begin the sentiment analysis. For this portion, we will continue working with the text that contains stop-words. The basic motivation behind sentiment analysis is to assess how positive or negative text is, based on a dictionary of words that have been previously classified as positive or negative. This type of dictionary is called a sentiment lexicon. The tidyverse has several built in lexicons for sentiment analysis, but for this example we will stick with ‘nrc’ and ‘bing’.The ‘nrc’ is a more advanced lexicon that categorizes words into several sentiment categories - sadness, anger, positive, negative, trust, etc. A single word in this lexicon may fall into multiple categories. Using the following code, we can get counts for the number of words in the Harry Potter series that fall into each of the categories addressed by ‘nrc’. In the output, you can see that there were 56579 words in the series that are classified as ‘negative’ by the ‘nrc’ lexicon. Overall, it looks like there are more negative words in the series than positive words. There are also a lot of words related to anger and sadness.
Get the lexicons we’ll be using by running these. You only have to do this once!
get_sentiments("afinn")
get_sentiments("bing")
get_sentiments("nrc")And then to see the in action
reverse_series %>%
right_join(get_sentiments("nrc")) %>%
filter(!is.na(sentiment)) %>%
count(sentiment,
sort = TRUE)## # A tibble: 10 × 2
## sentiment n
## <chr> <int>
## 1 negative 55093
## 2 positive 37758
## 3 sadness 34878
## 4 anger 32743
## 5 trust 23154
## 6 fear 21536
## 7 anticipation 20625
## 8 joy 13800
## 9 disgust 12861
## 10 surprise 12817The ‘bing’ lexicon only classifies words as positive or negative. Below you can see that this lexicon picked up 39503 negative words in the Harry Potter series, and 29066 positive words.
reverse_series %>%
right_join(get_sentiments("bing")) %>%
drop_na(sentiment) %>%
count(sentiment,
sort = TRUE)## # A tibble: 2 × 2
## sentiment n
## <chr> <int>
## 1 negative 39502
## 2 positive 29065Similarly to the word cloud we created above, we can use the ‘bing’ lexicon to make a comparison cloud. This cloud displays the 50 most frequently occurring words in the series that were categorized by ‘bing’, and color-codes them based on negative or positive sentiment. You’ll notice that words like Harry, Hermione and Ron don’t appear in this cloud, because character names are not classified as positive or negative in ‘bing’.
reverse_series %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment,
sort = TRUE) %>%
acast(word ~ sentiment,
value.var = "n",
fill = 0) %>%
comparison.cloud(colors = c("#d9534f", "#428bca"),
max.words = 50)
Now, let’s see what the comparison cloud looks like with stop-words removed temporarily3.
reverse_series %>%
anti_join(stop_words) %>%
inner_join(get_sentiments("bing")) %>%
count(word,
sentiment,
sort = TRUE) %>%
mutate(sentiment = factor(sentiment, levels = c("positive", "negative"))) %>%
acast(word ~ sentiment,
value.var = "n",
fill = 0) %>%
comparison.cloud(max.words = 50,
scale = c(3,.3),
title.bg.colors="transparent",
colors = c("#428bca", "#d9534f"),
match.colors = TRUE,
use.r.layout = TRUE,
title.size = 2)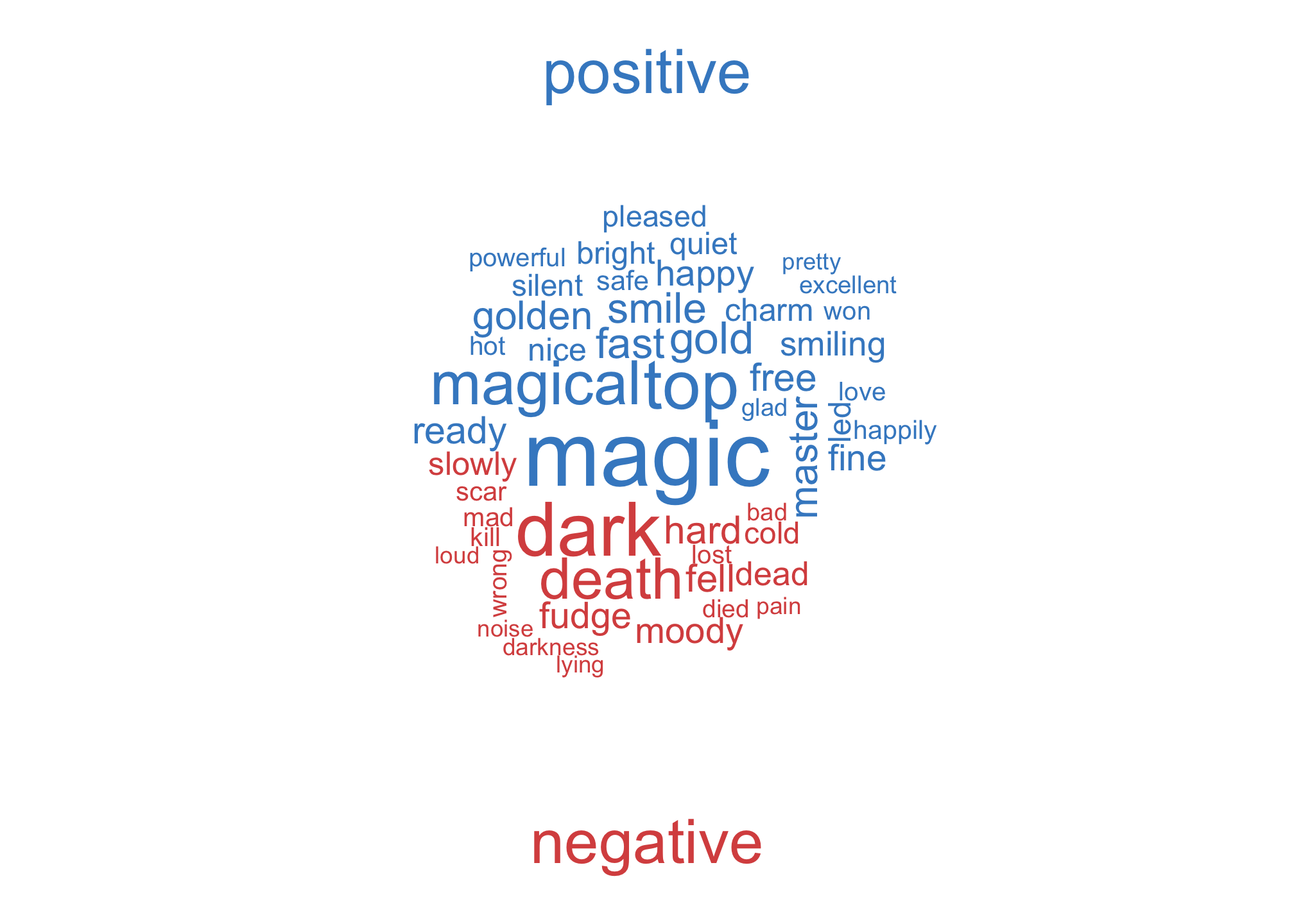
In the following code chunk, each book text is split into groups of 500 words, and counts for the number of positive and negative words in each group (based on the ‘bing’ lexicon) are calculated. Then we subtract the number of negative words from the number of positive words in each group. For example, if there were 341 positive words in a group and 159 negative words in the same group, the sentiment score for the group would be 182 (a positive sentiment score). We calculate this sentiment score for each 500 word group within each book in the series. Using ggplot, we create bar charts for each book in the series that demonstrate how the sentiment score for the text groups changes as time passes in the series. Overall, the sentiment of the Harry Potter series appears to be negative.
Challenges: How do these plots change if you go back and leave all of the stop-words in the tibble? Does the size of the text groups (500 words vs. 1000 words) affect the analysis?
As a next step, one might look at the maximum sentiment score and the minimum sentiment score for each book to see what text groups produced the extreme scores.
reverse_series %>%
group_by(book) %>%
mutate(word_count = 1:n(),
index = word_count %/% 500 + 1) %>%
inner_join(get_sentiments("bing")) %>%
count(book,
index = index ,
sentiment) %>%
ungroup() %>%
spread(sentiment,
n,
fill = 0) %>%
mutate(sentiment = positive - negative,
book = factor(book,
levels = titles)) %>%
ggplot(aes(index,
sentiment,
fill = book)) +
geom_bar(alpha = 0.5,
stat = "identity",
show.legend = FALSE) +
facet_wrap(. ~ book,
ncol = 2,
scales = "free_x") +
theme_minimal() +
scale_fill_viridis(discrete = "TRUE",
option = "C")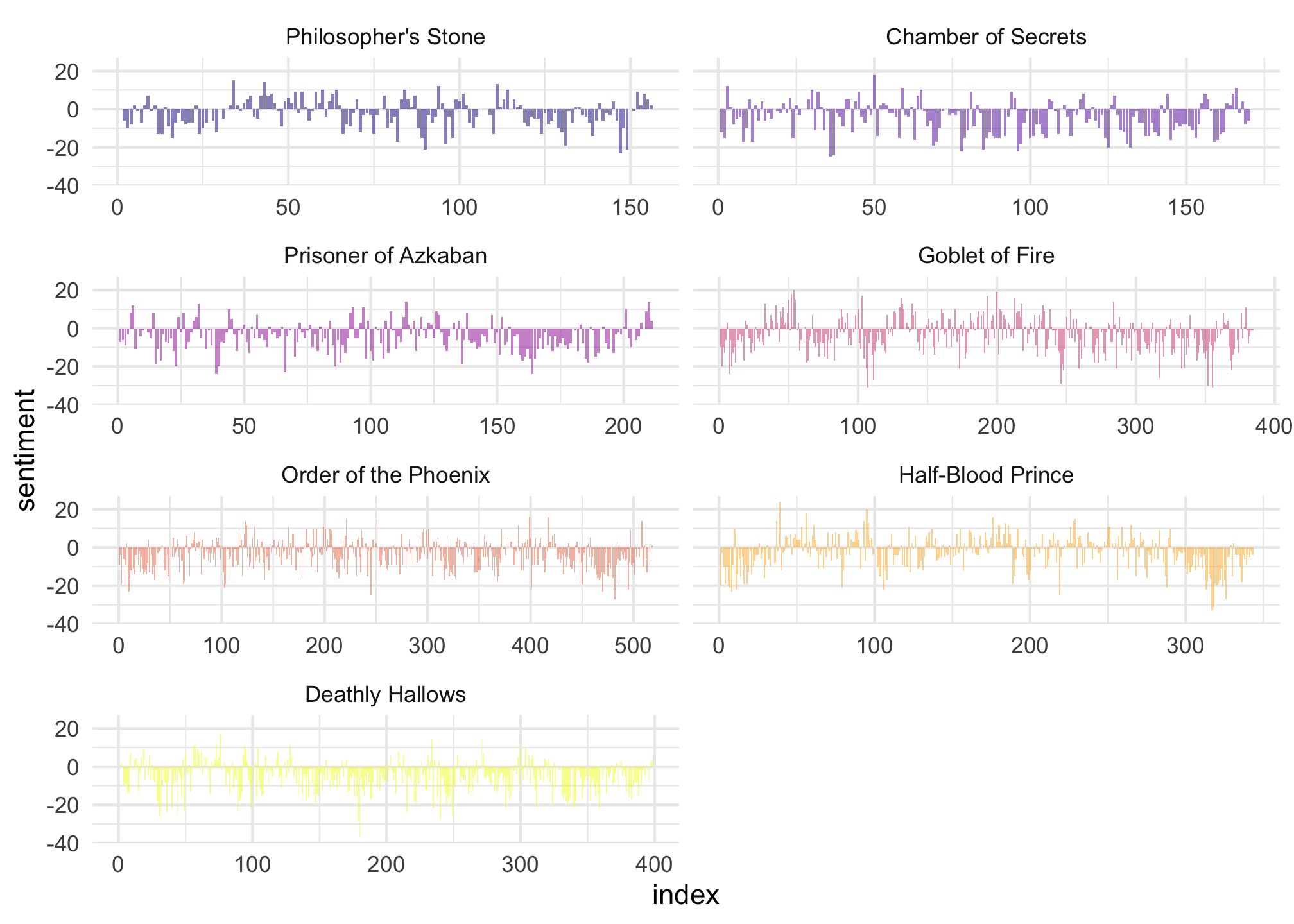
Using single words as tokens for sentiment analysis can be less than ideal. This is because nearby words add context - in particular, negations make the analysis tricky. For example, the word “good” is a positive word. However, “My day was not good” has a negative sentiment, despite the presence of the word “good”. A better example for the Harry Potter series would be that “magic” is considered to be a positive word, but “dark magic” would be have a negative meaning. For further analysis of our Harry Potter text, let’s look at pairs of words (bigrams). A bigram is a pair of words that appear consecutively in a text. For example, if we look at the sentence “I ate purple grapes”, the bigrams we can extract would be (I, ate), (ate, purple), and (purple, grapes). In the following code chunk, I repeat the process of shaping the text data from the beginning of the document, but this time I specify that bigrams should be used to tokenize the text rather than single words.
# determine bigrams
bigram_series <- tibble()
for(i in seq_along(titles)) {
temp <- tibble(chapter = seq_along(books[[i]]),
text = books[[i]]) %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2) %>%
## Here we tokenize each chapter into bigrams
mutate(book = titles[i]) %>%
select(book, everything())
bigram_series <- rbind(bigram_series, temp)
}
bigram_series## # A tibble: 1,089,186 × 3
## book chapter bigram
## <chr> <int> <chr>
## 1 Philosopher's Stone 1 the boy
## 2 Philosopher's Stone 1 boy who
## 3 Philosopher's Stone 1 who lived
## 4 Philosopher's Stone 1 lived mr
## 5 Philosopher's Stone 1 mr and
## 6 Philosopher's Stone 1 and mrs
## 7 Philosopher's Stone 1 mrs dursley
## 8 Philosopher's Stone 1 dursley of
## 9 Philosopher's Stone 1 of number
## 10 Philosopher's Stone 1 number four
## # … with 1,089,176 more rows# set factor to keep books in release order
reverse_bigram_series <-
bigram_series %>%
mutate(book = factor(book, levels = rev(unique(book)))) %>%
arrange(book)
reverse_bigram_series## # A tibble: 1,089,186 × 3
## book chapter bigram
## <fct> <int> <chr>
## 1 Deathly Hallows 1 the two
## 2 Deathly Hallows 1 two men
## 3 Deathly Hallows 1 men appeared
## 4 Deathly Hallows 1 appeared out
## 5 Deathly Hallows 1 out of
## 6 Deathly Hallows 1 of nowhere
## 7 Deathly Hallows 1 nowhere a
## 8 Deathly Hallows 1 a few
## 9 Deathly Hallows 1 few yards
## 10 Deathly Hallows 1 yards apart
## # … with 1,089,176 more rowsAgain, we can use the count function to find the most common bigrams in the series.
reverse_bigram_series %>%
count(bigram,
sort = TRUE)## # A tibble: 340,021 × 2
## bigram n
## <chr> <int>
## 1 of the 4895
## 2 in the 3571
## 3 said harry 2626
## 4 he was 2490
## 5 at the 2435
## 6 to the 2386
## 7 on the 2359
## 8 he had 2138
## 9 it was 2123
## 10 out of 1911
## # … with 340,011 more rowsAs we saw with the single words, most of the most common bigrams contain stop-words. Let’s remove those from our bigram tibble.
# separate the terms to edit them out
bigrams_separated <-
reverse_bigram_series %>%
separate(bigram,
c("word1", "word2"),
sep = " ")
bigrams_separated## # A tibble: 1,089,186 × 4
## book chapter word1 word2
## <fct> <int> <chr> <chr>
## 1 Deathly Hallows 1 the two
## 2 Deathly Hallows 1 two men
## 3 Deathly Hallows 1 men appeared
## 4 Deathly Hallows 1 appeared out
## 5 Deathly Hallows 1 out of
## 6 Deathly Hallows 1 of nowhere
## 7 Deathly Hallows 1 nowhere a
## 8 Deathly Hallows 1 a few
## 9 Deathly Hallows 1 few yards
## 10 Deathly Hallows 1 yards apart
## # … with 1,089,176 more rows# remove stop words from each
bigrams_filtered <-
bigrams_separated %>%
filter(!word1 %in% stop_words$word) %>%
filter(!word2 %in% stop_words$word)
bigrams_filtered## # A tibble: 137,629 × 4
## book chapter word1 word2
## <fct> <int> <chr> <chr>
## 1 Deathly Hallows 1 narrow moonlit
## 2 Deathly Hallows 1 moonlit lane
## 3 Deathly Hallows 1 wands directed
## 4 Deathly Hallows 1 other's chests
## 5 Deathly Hallows 1 wands beneath
## 6 Deathly Hallows 1 started walking
## 7 Deathly Hallows 1 walking briskly
## 8 Deathly Hallows 1 direction news
## 9 Deathly Hallows 1 replied severus
## 10 Deathly Hallows 1 severus snape.the
## # … with 137,619 more rows# merge the word columns back together to form bigrams
bigrams_united <-
bigrams_filtered %>%
unite(bigram, word1, word2, sep = " ")
bigrams_united## # A tibble: 137,629 × 3
## book chapter bigram
## <fct> <int> <chr>
## 1 Deathly Hallows 1 narrow moonlit
## 2 Deathly Hallows 1 moonlit lane
## 3 Deathly Hallows 1 wands directed
## 4 Deathly Hallows 1 other's chests
## 5 Deathly Hallows 1 wands beneath
## 6 Deathly Hallows 1 started walking
## 7 Deathly Hallows 1 walking briskly
## 8 Deathly Hallows 1 direction news
## 9 Deathly Hallows 1 replied severus
## 10 Deathly Hallows 1 severus snape.the
## # … with 137,619 more rows# count the updated bigrams
bigram_counts <-
bigrams_united %>%
count(bigram, sort = TRUE)
bigram_counts## # A tibble: 89,120 × 2
## bigram n
## <chr> <int>
## 1 professor mcgonagall 578
## 2 uncle vernon 386
## 3 harry potter 349
## 4 death eaters 346
## 5 harry looked 316
## 6 harry ron 302
## 7 aunt petunia 206
## 8 invisibility cloak 192
## 9 professor trelawney 177
## 10 dark arts 176
## # … with 89,110 more rowsNow that we have removed the stop-words, we can see that the most frequently occurring bigram in the series is “Professor McGonagall”. The only bigrams in the top ten that don’t contain character names are “Death Eaters”, “Invisibility Cloak” and “Dark Arts”.
Now, let’s use our bigrams to practice tf-idf (term frequency-inverse document frequency). In a nutshell, tf-idf is an analysis that seeks to identify how common a word is in a particular text, given how often it occurs in a group of texts. For example, Professor Lupin was a very prominent character in “The Prisoner of Azkaban”“, but not so much in the other books (and in the other books, he was not a professor). A person who had not read all of the books could determine this by simply counting the number of times the name”Professor Lupin” occurs in “The Prisoner of Azkaban” and comparing that number to the frequency of that bigram in the rest of the books in the series. To quantify this idea, the term frequency (the number of times a token appears in a document divided by the total number of tokens in the document) is multiplied by the inverse document frequency (the total number of documents divided by the number of documents containing the token). The chart below displays the ten bigrams with the highest tf-idf scores among the seven books in the series. “Professor Umbridge”, has the highest tf-idf score relative to “The Order of the Phoenix”. Any Harry Potter lover can tell you that we first meet Professor Umbridge in “The Order of the Phoenix”, in which and she plays a major role. In the other books in the series, her role ranges from small to non-existent. Thus, it makes sense that “Professor Umbridge” has a relatively high tf-idf score. Beneath the chart, there is a visual for the bigrams with the highest tf-idf scores.
# measure tf-idf
bigram_tf_idf <-
bigrams_united %>%
count(book, bigram) %>%
bind_tf_idf(bigram, book, n) %>%
arrange(desc(tf_idf))
bigram_tf_idf## # A tibble: 107,016 × 6
## book bigram n tf idf tf_idf
## <fct> <chr> <int> <dbl> <dbl> <dbl>
## 1 Order of the Phoenix professor umbridge 173 0.00533 1.25 0.00667
## 2 Prisoner of Azkaban professor lupin 107 0.00738 0.847 0.00625
## 3 Deathly Hallows elder wand 58 0.00243 1.95 0.00473
## 4 Goblet of Fire ludo bagman 49 0.00201 1.95 0.00391
## 5 Prisoner of Azkaban aunt marge 42 0.00290 1.25 0.00363
## 6 Deathly Hallows death eaters 139 0.00582 0.560 0.00326
## 7 Goblet of Fire madame maxime 89 0.00365 0.847 0.00309
## 8 Chamber of Secrets gilderoy lockhart 28 0.00232 1.25 0.00291
## 9 Half-Blood Prince advanced potion 27 0.00129 1.95 0.00252
## 10 Deathly Hallows deathly hallows 30 0.00126 1.95 0.00245
## # … with 107,006 more rows# factor the bigrams and rearrange according tf-idf
plot_potter <-
bigram_tf_idf %>%
arrange(desc(tf_idf)) %>%
mutate(bigram = factor(bigram,
levels = rev(unique(bigram)))) # plot the results
plot_potter %>%
top_n(20) %>%
ggplot(aes(bigram,
tf_idf,
fill = book)) +
geom_col() +
labs(x = NULL,
y = "tf-idf") +
coord_flip() +
theme_minimal() +
scale_fill_viridis(discrete = "TRUE",
option = "C")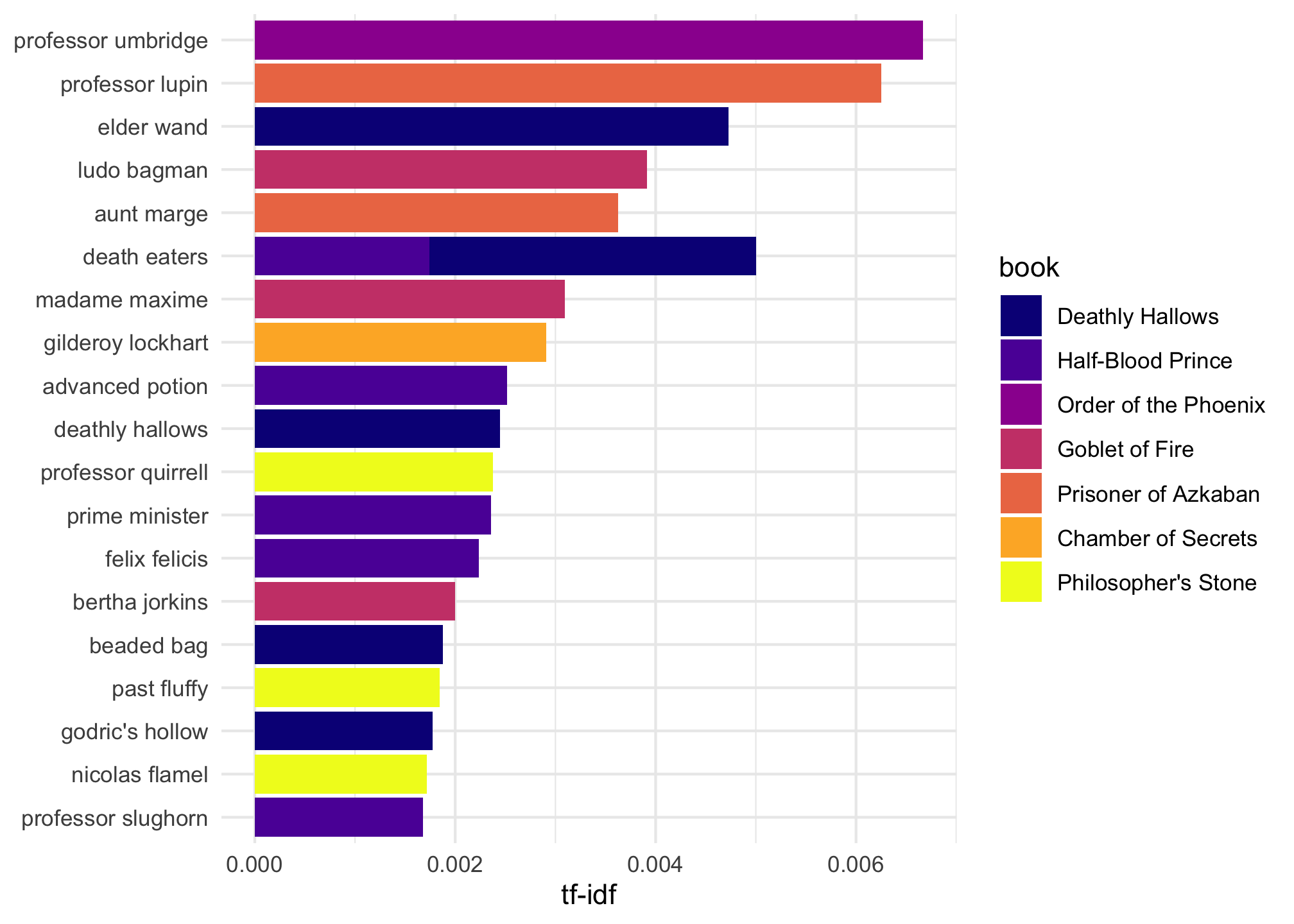
Now, to get an idea of how our sentiment analysis was affected by negations, let’s find all the bigrams that have the word “not” as the first word in the bigram.
bigrams_separated %>%
filter(word1 == "not") %>%
count(word1,
word2,
sort = TRUE)## # A tibble: 1,085 × 3
## word1 word2 n
## <chr> <chr> <int>
## 1 not to 383
## 2 not be 157
## 3 not a 131
## 4 not have 116
## 5 not the 103
## 6 not know 98
## 7 not going 92
## 8 not want 81
## 9 not said 76
## 10 not been 75
## # … with 1,075 more rowsThe first ten bigrams with “not” as the first word are boring, so let’s remove stop-words from the word2 column.
# use an anchor term (not)
bigrams_separated <-
bigrams_separated %>%
filter(word1 == "not") %>%
filter(!word2 %in% stop_words$word)%>%
count(word1, word2, sort = TRUE)
bigrams_separated## # A tibble: 824 × 3
## word1 word2 n
## <chr> <chr> <int>
## 1 not answer 41
## 2 not speak 41
## 3 not understand 35
## 4 not harry 32
## 5 not supposed 25
## 6 not dare 24
## 7 not hear 24
## 8 not allowed 22
## 9 not care 22
## 10 not knowing 17
## # … with 814 more rows# filter the negation bigrams
not_words <-
bigrams_separated %>%
filter(word1 == "not") %>%
filter(!word2 %in% stop_words$word)%>%
inner_join(get_sentiments("bing"),
by = c(word2 = "word")) %>%
ungroup()
not_words## # A tibble: 199 × 4
## word1 word2 n sentiment
## <chr> <chr> <int> <chr>
## 1 not bad 14 negative
## 2 not stupid 12 negative
## 3 not dead 9 negative
## 4 not daring 8 positive
## 5 not funny 8 negative
## 6 not hurt 7 negative
## 7 not blame 6 negative
## 8 not bother 6 negative
## 9 not pretend 6 negative
## 10 not afraid 5 negative
## # … with 189 more rowsJust looking at the top ten words in the list, we can see that most of the words that are preceded by “not” in the series, have negative sentiment. This means, we may be over estimating the negative sentiment present in the text. Of course, there are many other negation words such as “never”, “no”, etc. One could explore all of these possible negation words to get a better idea of how negation is affecting the sentiment analysis.
We can also create a graph that connects our most frequently occurring words with each other. Looking at the graph below, we can see a couple of larger clusters that give some context to what the series might be about. For example, there is a cluster with the word “professor” in the center, with several other words connected to it such as”McGonagall” and “Lupin”.
# convert to an igraph object
bigram_graph <-
bigram_counts %>%
filter(n > 35) %>%
as_tbl_graph()
bigram_graph## # A tbl_graph: 207 nodes and 138 edges
## #
## # A rooted forest with 69 trees
## #
## # Node Data: 207 × 1 (active)
## name
## <chr>
## 1 professor mcgonagall
## 2 uncle vernon
## 3 harry potter
## 4 death eaters
## 5 harry looked
## 6 harry ron
## # … with 201 more rows
## #
## # Edge Data: 138 × 2
## from to
## <int> <int>
## 1 1 139
## 2 2 140
## 3 3 141
## # … with 135 more rows# plot with a seed
set.seed(2017)
ggraph(bigram_graph,
layout = "fr") +
geom_edge_link(colour = "#bfbfbf") +
geom_node_point(color = "#428bca",
size = 5,
alpha = 0.3) +
geom_node_text(aes(label = name),
repel = TRUE,
check_overlap = FALSE) +
theme_graph()![]()
Word Correlations
Expanding on sentiments, it is also helpful to understand which pairs of words co-appear the texts. Let’s start with one of the texts..say Goblet of Fire and count the pairs of terms.
# use the goblet of fire text
gf_words <-
tibble(chapter = seq_along(goblet_of_fire),
text = goblet_of_fire) %>%
unnest_tokens(word, text) %>%
filter(!word %in% stop_words$word)
gf_words## # A tibble: 72,663 × 2
## chapter word
## <int> <chr>
## 1 1 villagers
## 2 1 hangleron
## 3 1 called
## 4 1 riddle
## 5 1 house
## 6 1 riddle
## 7 1 family
## 8 1 lived
## 9 1 stood
## 10 1 hill
## # … with 72,653 more rows# count common word pairs
word_pairs <-
gf_words %>%
pairwise_count(word,
chapter,
sort = TRUE)
word_pairs## # A tibble: 23,777,402 × 3
## item1 item2 n
## <chr> <chr> <dbl>
## 1 looked eyes 37
## 2 voice eyes 37
## 3 head eyes 37
## 4 harry eyes 37
## 5 time eyes 37
## 6 hand eyes 37
## 7 eyes looked 37
## 8 voice looked 37
## 9 head looked 37
## 10 harry looked 37
## # … with 23,777,392 more rowsYou can see that the output defaults to pairs of terms. Let’s say we just wanted to know about those associated with harry
# find counts between an anchor and words
word_pairs %>%
filter(item1 == "harry")## # A tibble: 9,918 × 3
## item1 item2 n
## <chr> <chr> <dbl>
## 1 harry eyes 37
## 2 harry looked 37
## 3 harry voice 37
## 4 harry head 37
## 5 harry time 37
## 6 harry hand 37
## 7 harry told 36
## 8 harry heard 36
## 9 harry harry's 36
## 10 harry people 35
## # … with 9,908 more rowsHowever, the terms that commonly appear together is generally just descriptive. While this type of assessment is nice, it doesn’t tell us much. Rather, we may also want to know how often words appear together with respect to their occurrence separately - aka the correlation among words which is measures in binary terms: yes they do or no they don’t. One common measure to gauge this type of correlation is given by the \(\phi\)4 coefficient. Take a look at the contingency table
| Word 1 included | Word 1 NOT included | Total | |
|---|---|---|---|
| Word 2 included | |||
| Word 2 NOT included | |||
| Total | Grand Total |
now translate that to something mathematical
| Word 1 included | Word 1 NOT included | Total | |
|---|---|---|---|
| Word 2 included | \(a\) | \(\mu\) | \(\zeta\) |
| Word 2 NOT included | \(m\) | \(\alpha\) | \(g\) |
| Total | \(z\) | \(\rho\) | Grand Total |
And we can measure \(\phi\) by \[\dfrac{a\cdot\alpha - m\cdot\mu}{\sqrt{z\cdot\zeta\cdot\rho\cdot g}}\]
or by using
word_cor <-
gf_words %>%
group_by(word) %>%
filter(n() >= 20) %>%
pairwise_cor(word, chapter) %>%
drop_na(correlation)
word_cor## # A tibble: 514,806 × 3
## item1 item2 correlation
## <chr> <chr> <dbl>
## 1 house called 0.345
## 2 family called 0.296
## 3 stood called 0.195
## 4 village called -0.0447
## 5 windows called -0.181
## 6 missing called -0.195
## 7 fine called -0.0903
## 8 half called -0.163
## 9 ago called 0.102
## 10 strange called 0.00641
## # … with 514,796 more rowsWe can also look at at the correlation with a particular term and plot it
# highest correlated words that appears with “potter”
word_cor %>%
filter(item1 == "potter") %>%
arrange(desc(correlation))## # A tibble: 717 × 3
## item1 item2 correlation
## <chr> <chr> <dbl>
## 1 potter odd 0.585
## 2 potter stood 0.536
## 3 potter telling 0.512
## 4 potter slowly 0.471
## 5 potter class 0.445
## 6 potter minutes 0.444
## 7 potter ears 0.441
## 8 potter straight 0.441
## 9 potter fourth 0.422
## 10 potter witch 0.422
## # … with 707 more rows# visualize the correlations within word clusters
set.seed(123)
gf_words %>%
group_by(word) %>%
filter(n() >= 20) %>%
pairwise_cor(word, chapter) %>%
filter(!is.na(correlation),
correlation > .65) %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_node_point(color = "#5cb85c",
size = 5,
alpha = 0.3) +
geom_edge_link(aes(edge_alpha = correlation),
show.legend = FALSE) +
geom_node_text(aes(label = name),
repel = TRUE) +
theme_graph()
That’s it for text analytics with the Harry Potter series.This is by no means a comprehensive analysis, but it should have demonstrated some of the basic facets of mostly tidy text mining in R.
Consider just pasting it at the top of your script and leaving it there. Please note that this will not work in an Rmarkdown file or Shiny app.↩︎
Note that if you run a package update through RStudio, it will overwrite the one we use with the one on CRAN.↩︎
Yours will probably look a bit different but that is OK!↩︎
written phi and pronounced fee or fi depending on who you ask↩︎